Régression multivariables - incertitudes

dans Statistiques
Bonjour à tous.
J'espère m'adresser à la bonne partie du forum. Je suis plutôt novice en statistiques.
Je possède un jeu de données expérimentales, obtenu par un procédé sur lequel le contrôle des paramètres d'entrée est plutôt fin.
Ma sortie $Y$ est fonction de trois entrées \[Y = f(X_1, X_2, X_3).
\] Je souhaite effectuer une régression par un polynôme de degré $n$. Jusque là, pas de soucis a priori, cela se fait très bien avec python et sklearn par exemple.
Mon souci se porte sur le choix de la méthode. En effet, ma sortie $Y$ peut varier pour un même vecteur d'entrée $X$. Par exemple : \[f(300,2.5,0) = 0.7 \\ f(300,2.5,0) = 0.72 \\ f(300,2.5,0) = 0.69 \\ f(300,2.5,0) = 0.81\\
{\rm etc~} ...
\] J'aurais voulu savoir s'il y avait des méthodes spécifiques tenant compte de la variation de $Y$, ou bien si les méthodes usuelles suffisent. J'ai effectué des recherches, sans réponses probantes. J'utilise exclusivement python pour les calculs.
En espérant avoir été clair,
Merci d'avance.
J'espère m'adresser à la bonne partie du forum. Je suis plutôt novice en statistiques.
Je possède un jeu de données expérimentales, obtenu par un procédé sur lequel le contrôle des paramètres d'entrée est plutôt fin.
Ma sortie $Y$ est fonction de trois entrées \[Y = f(X_1, X_2, X_3).
\] Je souhaite effectuer une régression par un polynôme de degré $n$. Jusque là, pas de soucis a priori, cela se fait très bien avec python et sklearn par exemple.
Mon souci se porte sur le choix de la méthode. En effet, ma sortie $Y$ peut varier pour un même vecteur d'entrée $X$. Par exemple : \[f(300,2.5,0) = 0.7 \\ f(300,2.5,0) = 0.72 \\ f(300,2.5,0) = 0.69 \\ f(300,2.5,0) = 0.81\\
{\rm etc~} ...
\] J'aurais voulu savoir s'il y avait des méthodes spécifiques tenant compte de la variation de $Y$, ou bien si les méthodes usuelles suffisent. J'ai effectué des recherches, sans réponses probantes. J'utilise exclusivement python pour les calculs.
En espérant avoir été clair,
Merci d'avance.
Réponses
-
Bonjour,
Les techniques usuelles de régression (et non d'interpolation) suffisent. Dans ton cas tu pourrais éventuellement exploiter des techniques bayésiennes pour déterminer le niveau de bruit dans tes données, plutôt que le fixer arbitrairement (pour mettre à profit le fait que tu as plusieurs observations $y$ pour un $x$ donné).
(Dans une vision non-probabiliste d'optimisation de fonctionnelle, par exemple pour la technique de régression ridge, cela revient à ajuster automatiquement le facteur de pondération $\lambda$ des termes d'attache aux données et de régularisation. D'ailleurs scikit learn propose par exemple de la régression ridge bayésienne entre autres joyeusetés.). -
Bonjour,
D'après ce que tu dis, oui la régression polynomiale est possible mais je suis très surpris par ta question. Tu devrais savoir à quoi correspond la sortie du modèle : espérance...Cela serait bien de connaître ses basiques avant de passer à des modèles plus complexes.
Pour tout ce qui concerne ta question, cela serait bien d'étudier le chapitre correspondant dans le livre téléchargeable "An introduction to statistical learning" chez Springer.
Bon courage. -
Bonjour,
Je fais cette remarque aussi, après le recueil et la mise en forme des données (grosso modo 90% du temps), il y a la partie informatique avec des librairies comme scikit-learn. Il y aussi la capacité d'interprèter les listings obtenus ce qui demande un peu de théorie ou alors de suivre des procédures sans trop se poser de questions.
Cordialement. -
Bonjour,
Merci beaucoup pour la réponse et les précisions. Les techniques de regression bayesiennes sont exactement ce que je recherchais. Désolé pour mon manque de vocabulaire mathématiques : la dernière fois que j'en ai fait, c'était en prépa, et depuis je n'en ai quasiment plus de manière formelle (juste de l'utilisation pratique en ingénierie et en doctorat). J'ai des notions élémentaires en statistiques, mais manque de rigueur et de vocabulaire précis.
Pour mettre le contexte expérimental, j'étudie, en science des matériaux, l'influence des paramètres (X) d'un procédé de projection thermique sur une caractéristique de mon matériau (taux de porosité, que j'appelle Y).
Ma sortie Y correspond bien à une probabilité (je connais son espérance et sa variance, calculées a posteriori).J'ai également peu de points X en entrée, ce qui me semble limite pour vraiment faire une statistique ( < 10 points). Cela est du au fait que l'élaboration d'échantillons, les techniques de préparation et de caractérisations sont longues et coûteuses.
Pour vous donner une idée graphique, mon nuage de points pourrait avoir cette allure en 2D :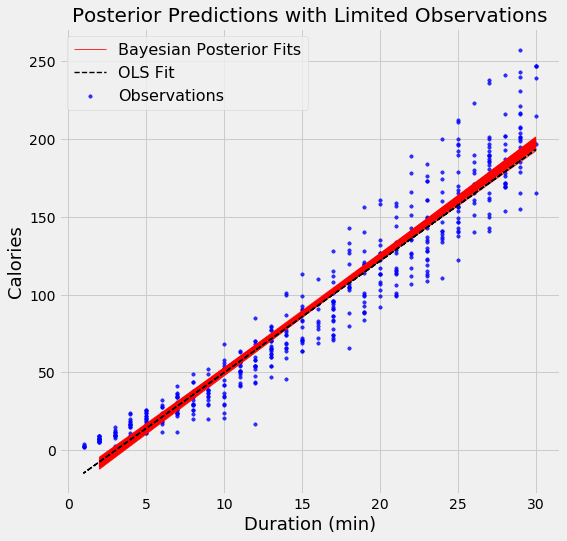
La regression m'est utile pour ensuite pour obtenir une fonction f=(X1,X2,X3) (idéalement un polynôme) sur laquelle effectuer une analyse de sensibilité (type Sobol).
Bonne journée. -
Bonjour,
Quel est le sens de ce message??? À part vouloir se rattraper aux branches, je ne vois pas. Il faut faire attention car sur le graphique : il y a plusieurs observations pour une même abscisse. Si, c'est pour poser une question simple puis envoyer un message à rallonge digne d'une thèse ;-): il y a une perte de temps des deux côtés. Je t'indique que modéliser des probabilités implique, en général d'avoir des valeurs comprises entre 0 et 1. Comme disait, Ponce Pilate, en période d'épidémie...
Bonne continuation (de quoi, je ne le sais plus vraiment)


Connectez-vous ou Inscrivez-vous pour répondre.
Bonjour!
Catégories
- 163.1K Toutes les catégories
- 8 Collège/Lycée
- 21.9K Algèbre
- 37.1K Analyse
- 6.2K Arithmétique
- 53 Catégories et structures
- 1K Combinatoire et Graphes
- 11 Sciences des données
- 5K Concours et Examens
- 11 CultureMath
- 47 Enseignement à distance
- 2.9K Fondements et Logique
- 10.3K Géométrie
- 62 Géométrie différentielle
- 1.1K Histoire des Mathématiques
- 68 Informatique théorique
- 3.8K LaTeX
- 39K Les-mathématiques
- 3.5K Livres, articles, revues, (...)
- 2.7K Logiciels pour les mathématiques
- 24 Mathématiques et finance
- 312 Mathématiques et Physique
- 4.9K Mathématiques et Société
- 3.3K Pédagogie, enseignement, orientation
- 10K Probabilités, théorie de la mesure
- 772 Shtam
- 4.2K Statistiques
- 3.7K Topologie
- 1.4K Vie du Forum et de ses membres
Qui est en ligne 13



 +9 Invités
+9 Invités