Éléments les plus éloignés dans une matrice2D

dans Statistiques
Bonjour
J'ai un problème qui me casse la tête depuis plusieurs jours.
J'ai une matrice en deux dimensions qui me calcule le taux de similitude entre plusieurs textes.
Ce que je cherche à faire c'est un classement des textes les plus éloignés entre eux (donc le plus possible avec un faible pourcentage entre chacun d'entre eux).
Dans mon classement, je préfère avoir beaucoup de textes moyennement proches les uns entre les autres que peu de textes très éloignés.
J'ai essayé de calculer des moyennes de similitude en enlevant les valeurs les plus éloignées, des calculs sur les pourcentages + les occurrences, mais je ne trouve jamais un classement cohérent et je suis presque sûr qu'il y a une formule ou une manière de faire.
Voilà un exemple de matrice :
D'une manière générale, il faut que le 4 et le 3 soient éloignés cars 49% similaire. Mais il faut aussi que le 2 et le 3 soient éloignés. Pour le reste, c'est un classement des plus petits pourcentages entre eux. 5 et 4 parce qu'ils n'ont que 4%. Ensuite j'ai regardé lequel avait le moins de pourcentage avec et le 5 et le 4 -> le 1.
Par contre si le 1 avait 50% avec le 5 et 5% avec le 4 et que le 2 avait 27% avec le 5 et 25% avec le 4, j'aurais préféré le 2. Car il est certes plus similaire avec les 2 mais il n'y a pas un gros écart. Le texte 1 fausserait tout avec un aussi gros pourcentage de similarité.
Si on prend un deuxième exemple :
Mais encore une fois c'est sans calculs et je pense qu'il y a une manière de calculer ça précisément.
L'idéal serait d'avoir des données et des statistiques comme ces courbes :
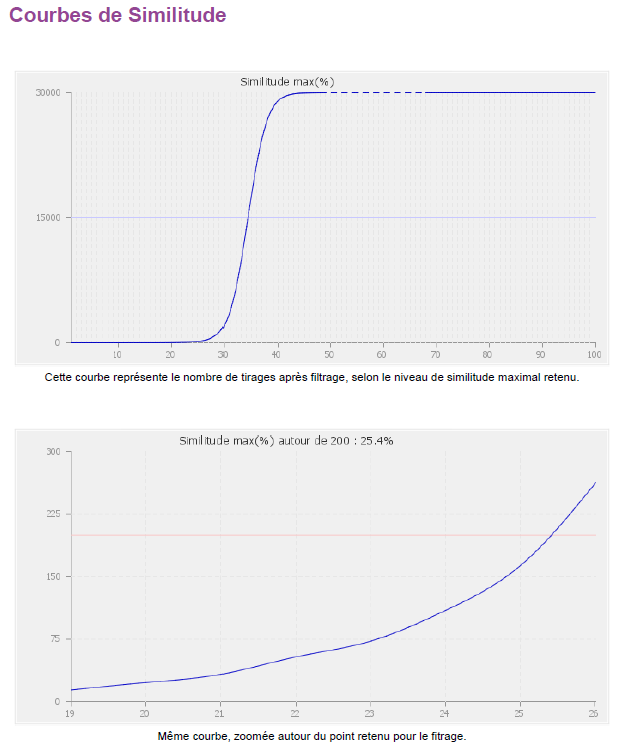
En indiquant un certain nombre de textes, indiqué quel serait le taux de similitude maximal.
Mon but est d'exporter un maximum de textes avec le moins de pourcentage de similitude possible.
J'espère que vous aurez compris ma demande ! Je suis dispo si vous avez des questions !
Bonne journée
J'ai un problème qui me casse la tête depuis plusieurs jours.
J'ai une matrice en deux dimensions qui me calcule le taux de similitude entre plusieurs textes.
Ce que je cherche à faire c'est un classement des textes les plus éloignés entre eux (donc le plus possible avec un faible pourcentage entre chacun d'entre eux).
Dans mon classement, je préfère avoir beaucoup de textes moyennement proches les uns entre les autres que peu de textes très éloignés.
J'ai essayé de calculer des moyennes de similitude en enlevant les valeurs les plus éloignées, des calculs sur les pourcentages + les occurrences, mais je ne trouve jamais un classement cohérent et je suis presque sûr qu'il y a une formule ou une manière de faire.
Voilà un exemple de matrice :
0 1 2 3 4 5 1 100% 19% 37% 12% 20% 2 19% 100% 48% 34% 26% 3 37% 48% 100% 49% 18% 4 12% 34% 49% 100% 4% 5 20% 24% 18% 4% 100%Dans ce cas là, mon ordre personnel serait 5, 4, 1, 2, 3. Mais c'est sans calcul ...
D'une manière générale, il faut que le 4 et le 3 soient éloignés cars 49% similaire. Mais il faut aussi que le 2 et le 3 soient éloignés. Pour le reste, c'est un classement des plus petits pourcentages entre eux. 5 et 4 parce qu'ils n'ont que 4%. Ensuite j'ai regardé lequel avait le moins de pourcentage avec et le 5 et le 4 -> le 1.
Par contre si le 1 avait 50% avec le 5 et 5% avec le 4 et que le 2 avait 27% avec le 5 et 25% avec le 4, j'aurais préféré le 2. Car il est certes plus similaire avec les 2 mais il n'y a pas un gros écart. Le texte 1 fausserait tout avec un aussi gros pourcentage de similarité.
Si on prend un deuxième exemple :
0 1 2 3 4 5 1 100% 8% 14% 20% 11% 2 8% 100% 19% 4% 6% 3 14% 19% 100% 21% 6% 4 20% 4% 21% 100% 15% 5 11% 6% 6% 15% 100%Ici mon classement serait : 5, 2, 4, 1, 3
Mais encore une fois c'est sans calculs et je pense qu'il y a une manière de calculer ça précisément.
L'idéal serait d'avoir des données et des statistiques comme ces courbes :

En indiquant un certain nombre de textes, indiqué quel serait le taux de similitude maximal.
Mon but est d'exporter un maximum de textes avec le moins de pourcentage de similitude possible.
J'espère que vous aurez compris ma demande ! Je suis dispo si vous avez des questions !
Bonne journée
Connectez-vous ou Inscrivez-vous pour répondre.
Bonjour!
Catégories
- 163.2K Toutes les catégories
- 9 Collège/Lycée
- 21.9K Algèbre
- 37.1K Analyse
- 6.2K Arithmétique
- 53 Catégories et structures
- 1K Combinatoire et Graphes
- 11 Sciences des données
- 5K Concours et Examens
- 11 CultureMath
- 47 Enseignement à distance
- 2.9K Fondements et Logique
- 10.3K Géométrie
- 65 Géométrie différentielle
- 1.1K Histoire des Mathématiques
- 69 Informatique théorique
- 3.8K LaTeX
- 39K Les-mathématiques
- 3.5K Livres, articles, revues, (...)
- 2.7K Logiciels pour les mathématiques
- 24 Mathématiques et finance
- 314 Mathématiques et Physique
- 4.9K Mathématiques et Société
- 3.3K Pédagogie, enseignement, orientation
- 10K Probabilités, théorie de la mesure
- 773 Shtam
- 4.2K Statistiques
- 3.7K Topologie
- 1.4K Vie du Forum et de ses membres
Qui est en ligne 32










 +21 Invités
+21 Invités